Pourquoi utiliser un Internal Developer Portal ?

Internal Developer Platform
On parle régulièrement des Internal developer platform, IDP. Et, il est tout à fait possible que vous ne connaissiez pas cet acronyme, mais que vous en utilisiez pourtant tous les jours si vous travaillez dans l'Engineering.
C'est la colonne vertébrale pour construire, tester et déployer une application.
Son but est de cacher la complexité et d'accélérer la capacité à construire le logiciel.
C'est personnellement ce que j'appelais "usine logicielle" il y a encore quelques années.
Bref, vous connaissez donc déjà.
Un IDP peut prendre différentes formes. Un PAAS peut être un IDP dans le sens ou c'est la colonne vertébrale qui permet de construire l'application (même s'il manque souvent la partie CI).
Tout ce qui concerne l'ensemble des opérations d'automatisation de votre infrastructure entre dans la définition de votre IDP.
Une fois qu'on a dit ça, vous avez compris que l'IDP est incontournable dans une équipe de développement pour garantir et booster la vélocité d'une équipe.
La grande tendance de ces dernières années autour de l'automatisation, l'infrastructure as code, l'orchestration, la gestion des environnements, du déploiement, tout cela a contribué à accélérer drastiquement la capacité des équipes Produit.
On l'oublie facilement, mais le temps n'est pas si lointain où la majorité des entreprises livraient de façon trimestrielle, voire semestrielle.
Pire, chaque nouvelle version du logiciel mobilisait des dizaines de personnes sur plusieurs jours.
L'industrie a fait d'énormes progrès dans le domaine de l'automatisation et des usines logicielles, couplés avec la souplesse du cloud (mise à disposition d'environnement plus rapide) pour permettre désormais un rythme de mise en production journalier, sans quasi aucune action humaine.
Si vous ne connaissez pas les DORA metrics, elles sont utilisées depuis quelques années pour mesurer l'efficacité des équipes Engineering. Et l'une de ces métriques concerne justement la fréquence de déploiement.
Une équipe performante déploie a minima toutes les semaines, mais bien souvent plusieurs fois par jour. Chose permise par les usines logicielles modernes, ou internal developer platform si vous avez bien suivi.
A ce stade de la lecture, je ne pense pas avoir besoin d'expliquer davantage l'intérêt de ces plateformes (*) et du bénéfice qu'elles ont apporté à toute l'industrie.
(*) Le but de ce billet n'est pas de parler des équipes plateformes, mais implicitement, vous comprendrez que ces équipes sont clés pour la santé globale de l'Engineering et sa capacité à délivrer du logiciel.
Internal Developer Portal
Aujourd'hui on entend de plus en plus souvent parler des internal developer portal. À partir de maintenant dans ce billet j'utiliserais l'acronyme IDP pour y faire référence.
Un Internal Developer Portal ne doit pas être confondu avec l'Internal Developer Platform. Mais il en fait partie.
Un Internal Developer portal se veut comme l'interface unifiée devant l'ensemble des outils offerts par une internal developer platform.
Et donc là encore, vous utilisez sans doute déjà un IDP même si vous ne connaissez pas le nom. Ou plus exactement, vous avez sans doute déjà vu des parties d'un IDP.
C'est par exemple votre tableau de bord de CI :
C'est peut-être votre tableau de bord argocd pour vos déploiements :
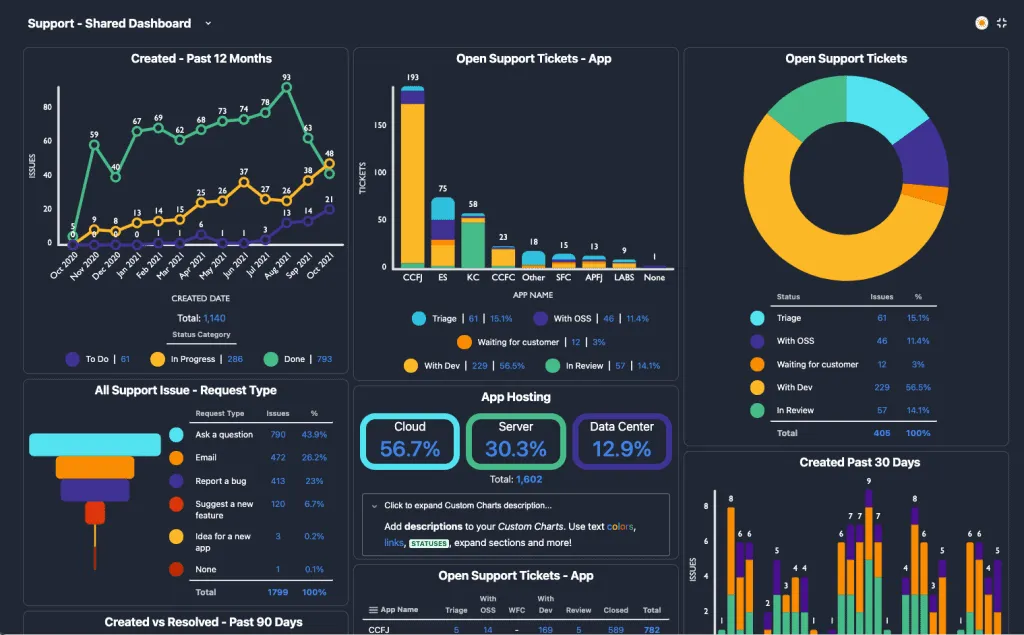
Vous avez peut-être déjà regroupé tout un ensemble d'informations dans un Board Jira, ce qui est déjà un usage avancé.
Mais en plus de ces quelques outils, il est souvent nécessaire de consulter une multiplicité de produits. Voici par exemple un mindmap de ce que cela représente chez Malt.
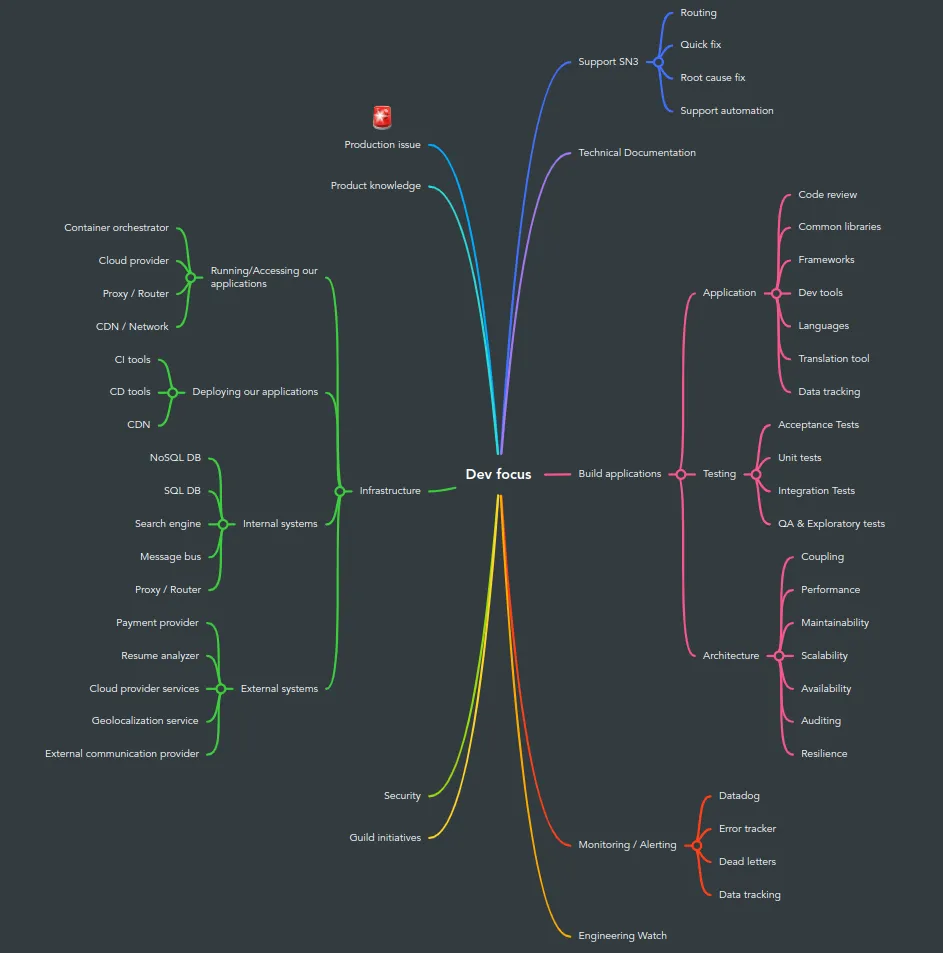
Bref, une personne dans une équipe produit doit jongler avec des produits de :
- ticketing (jira, github issues etc..)
- alerting (sentry, datadog)
- alerting de sécurité (snyk, dependabot...)
- wiki et documentation (notion, confluence, miro...)
- repository git (gitlab, github...)
- usine logicielle (gitlab CI, github actions, circle CI...)
- canaux de communication (slack, teams, emails...)
- plateforme(s) de déploiement (console cloud, PAAS, argocd)
- outils de monitoring (datadog, prometheus, grafana)
La surcharge d'informations est faramineuse comparée avec la stack que je pouvais utiliser début des années 2000.
Attention, il ne faut pas comprendre de travers. Cette stack est aussi celle qui a permis de faire un saut de géant dans l'industrie sur le rythme de livraison et la qualité logicielle.
Mais cette stack mériterait d'être simplifiée, ou plutôt centralisée. Ce qui est le but des IDP : regrouper l'ensemble de l'information.
Car cette décentralisation se transforme souvent en perte de temps, et donc d'argent.
Reprenons le mindmap vu plus haut, le cycle de développement est ponctué par de nombreuses questions qui se traduisent en interruptions permanentes :
- Qui s'occupe de ce service ?
- Quand a-t-il été déployé ou modifié pour la dernière fois ?
- Est-ce que j'ai reçu des alertes en production ?
- De quelle nature, à quelle version du logiciel cela correspond ?
- Est-ce que quelqu'un travaille dessus ?
- Qui faut-il prévenir si je mets à jour ce composant ?
- Où en est-on sur l'initiative X lancée le mois dernier ?
- Combien coûte le service que j'ai déployé en production ? Est ce normal ?
- Comment ajouter un nouveau service sur le système ?
- Comment m'assurer que mon service tourne avec le bon dimensionnement mémoire et CPU ?
- Comment changer ces paramètres si besoin ?
Et bien sûr le produit ne travaille pas en isolation. D'autres équipes ont besoin parfois des mêmes réponses.
- Qui s'occupe de cette fonctionnalité ?
- Quel est le channel slack pour contacter les bonnes personnes si elle ne fonctionne pas ou si je veux en discuter ?
- Est-ce que la fonctionnalité annoncée lors du dernier Product Meeting est déjà disponible ? Comment elle marche exactement ? où est la documentation ?
L'Internal developer portal a pour vocation de rassembler l'information à un seul et même endroit.
Il se compose bien souvent de plusieurs briques majeures :
- le service catalog
- le portail d'automatisation
- la définition de scorecards
- le cost management
Le sujet est désormais très populaire. Thoughtworks et Forrester ont sorti une étude en 2023 pour mesurer les pratiques logicielles liées aux plateformes de développement.
Dans cette étude, il apparaît que 78% des équipes prévoient de mettre en place un internal developer portal.
Gartner en fait une recommandation récente en 2022.
Bref, si tout cet écosystème a le vent en poupe, c'est parce qu'il permet de booster la productivité des équipes.
Les Internal developer portal ont vocation de réduire le temps perdu par une équipe d'ingénierie (nous verrons comment plus bas).
Nous allons considérer ce gain de temps moyen entre 5 et 15% sur l'année.
Ce sera donc un gain :
- de 250 à 750k de gain pour une équipe de 50 personnes.
- de 500k à 1.5M de gain pour une équipe de 100 personnes
- de 2.5M à 7.5M de gain pour une équipe de 500 personnes.
On comprend assez vite l'importance du sujet.
TIP
Ce gain n'est pas linéaire. La perte d'informations étant plus grande à mesure que l'équipe grandit, le gain apporté par un IDP grimpe avec la taille de l'équipe. A l'inverse, il est beaucoup plus faible pour des équipes de petite taille. C'est la taille d'équipe qui pose des problèmes de partage d'infos et de coordination.
Voyons les différentes briques d'un IDP.
Le service catalog
Le Service Catalog c'est tout simplement l'inventaire de toutes les applications, librairies, services dont vous êtes responsable.
Avant, on parlait de cartographier le système. C'est juste nécessaire pour savoir qui s'occupe de quel service, qui contacter en cas de questions.
Un service catalog peut aussi modéliser les relations entre les composants, ou lister les canaux de communication, la personne d'astreinte, les garanties de services.
Quand le service catalog est dynamique, il peut aussi indiquer l'état de santé d'un composant, les alertes connues etc...
C'est souvent à cette étape qu'on retrouve une pléthore de Service Catalog.
- celui de votre CI
- celui de votre outil de déploiement
- celui de votre environnement cloud
Et comme si cela ne suffisait pas, à partir d'une certaine taille et pour donner la même info en dehors de l'équipe Engineering vous avez sans doute aussi un fichier Excel qui ressemble à ça :
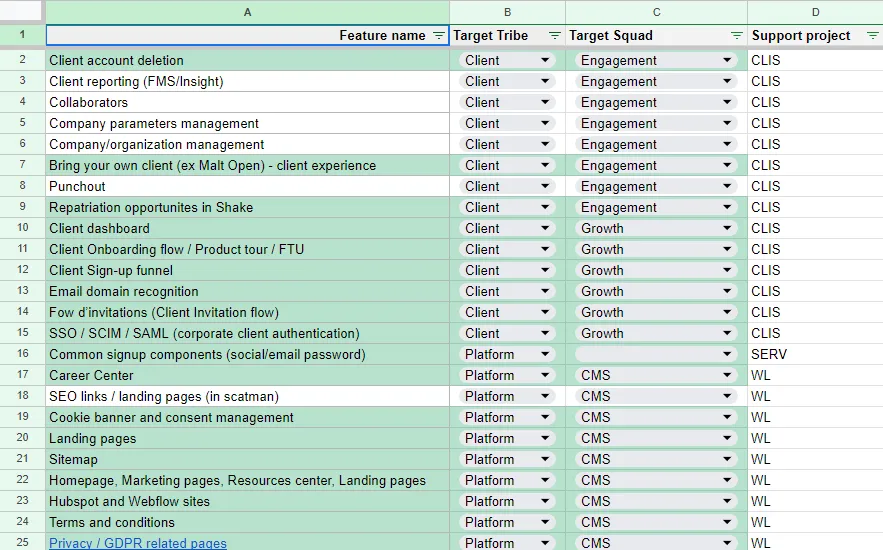
(Chez Malt ce fichier contient 120 lignes)
À partir de là, on commence à toucher du doigt un premier gros problème d'inefficacité, ces différents services catalog peuvent se contredire, utiliser des noms de composants qui ne se recoupent pas, demander une maintenance manuelle.
Lorsque ces outils donnent une information erronée ou partielle, c'est une source infinie de problèmes. Ce sont des pertes de temps pour trouver les bonnes personnes, ce sont des erreurs de traitements des alertes, du context switching des personnes qui vont essayer de comprendre les disparités.
Et le temps, c'est de l'argent.
L'éclatement de tous ces produits crée aussi une forme d'"Alert fatigue".
Si je reçois des alertes sur différents canaux de Datadog, Sentry, GitlabCI, Phrase, Snyk, Sonar, etc. Qu'est-ce je dois regarder en premier ?
Si cela sonne sans arrêt, est-ce grave ?
D'autant plus si une grande partie de ces alertes sont mal ciblées et ne me concernent pas quand les sources de données sont tellement disparates que les alertes qui en résultent sont forcément mal configurées.
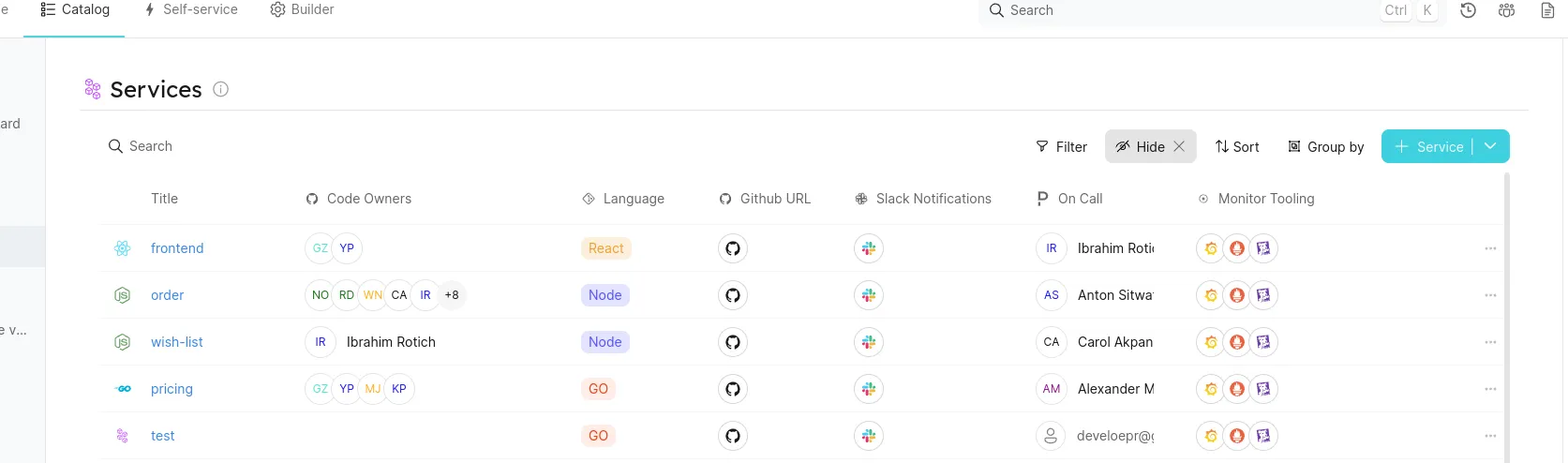
L'une des fonctionnalités clés d'un IDP est de centraliser l'information de plusieurs sources de données et de garantir qu'il n'y ait qu'une seule source de vérité.
L'agrégation permet d'avoir d'un coup d'œil la corrélation entre les données venant du monitoring, de la sécurité ou de savoir qui gère le service, son état de santé, le canal de communication de l'équipe concernée.
Exemple avec le catalogue de getport
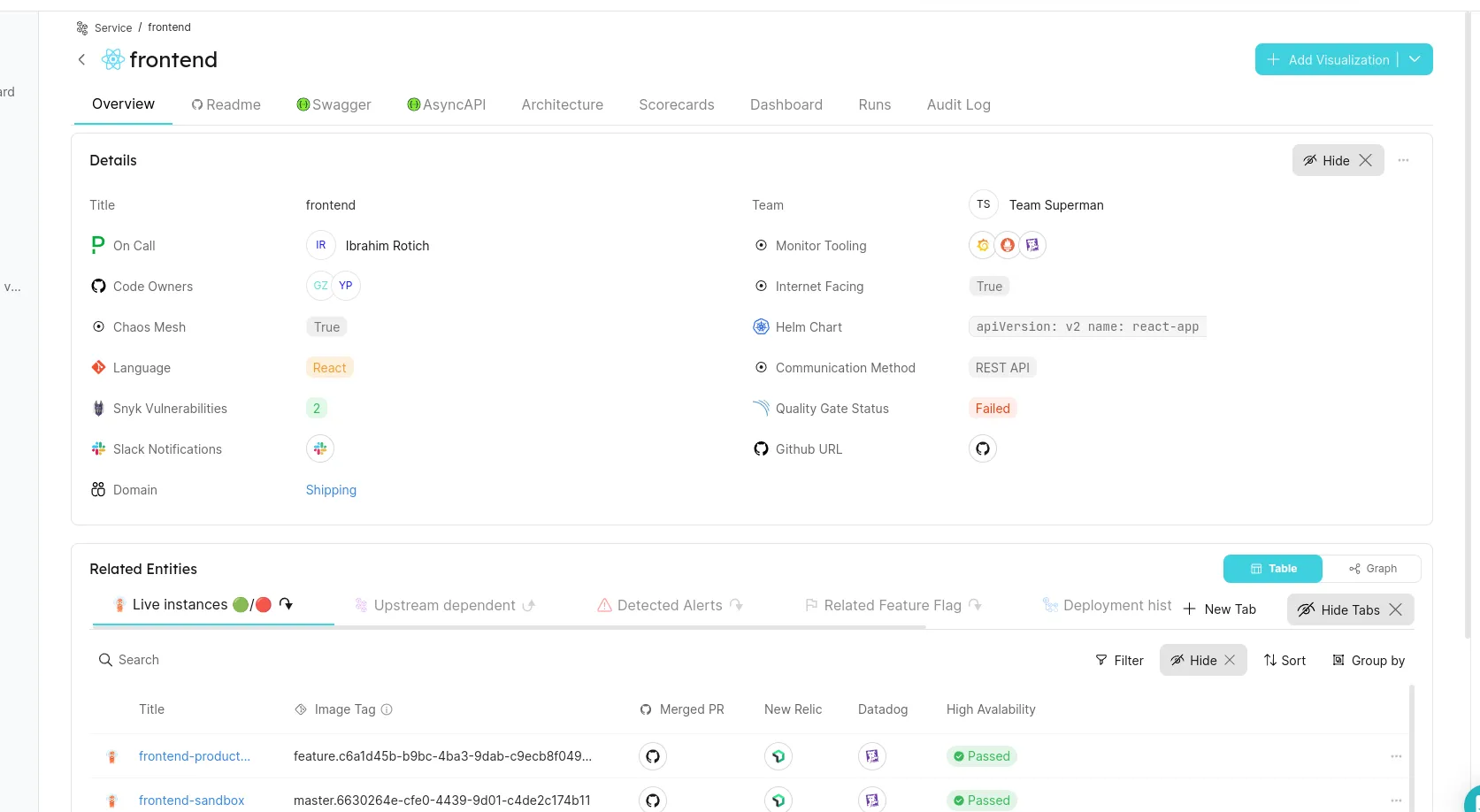
Ou avec la fenêtre de détail d'une application :
Le portail d'automatisation
Je le disais plus haut, les internal developer platform ont permis des gains monstrueux en productivité.
Mais la complexité des systèmes, notamment dans des environnements cloud et des environnements distribués fait que la plupart des opérations sont souvent peu accessibles à tous les développeurs et développeuses.
Ajouter un secret dans la CI ou sur votre cloud provider via terraform. Ok c'est une garantie de le faire correctement, checké par une CI, reproductible lorsqu'il faudra remonter l'environnement. Mais c'est aussi de nouvelles compétences à connaître.
Ajouter un nouveau service, savoir le configurer dans une multitude de produits pour qu'il soit correctement monitorés, construits sur la CI, déployés, là encore, c'est souvent nécessaire de demander de l'aide.
Et le nombre d'exemples de même nature ne manque pas : obtenir un certificat de sécurité personnel, initialiser des jeux de données et des middlewares locaux, dimensionner correctement son application en production, récupérer des logs de crash dump etc...
Ici, vous avez deux options. Vous recrutez énormément dans l'équipe Ops ou bien, vous diffusez les connaissances à tout le monde, d'où le fameux mouvement Devops. Dans la pratique, la charge cognitive est telle qu'il y a souvent quelques personnes qui finissent par se charger de tout cela et qui finissent par devenir des SPOF (single point of failure) humains. C'est éreintant pour ces personnes, frustrant pour les autres.
Mais il y a une alternative. Faire en sorte que les personnes qui centralisent une grande partie du RUN fassent du BUILD pour construire des interfaces simplifiées au sein de l'Internal Developer platform pour que chaque opération soit présentée de manière simple, documentée, centralisée.
On parle aussi d'une approche "Platform teams". L'article sur le site de Martin Fowler est bien plus large que cela. Mais imaginez l'Internal Developer Platform construit comme un produit, par une équipe centralisée dont le but est de rendre autonome ces utilisateurs, qui sont les équipes Produit.
Et imaginez l'ensemble des actions présenté sous forme de portail d'actions en self service :
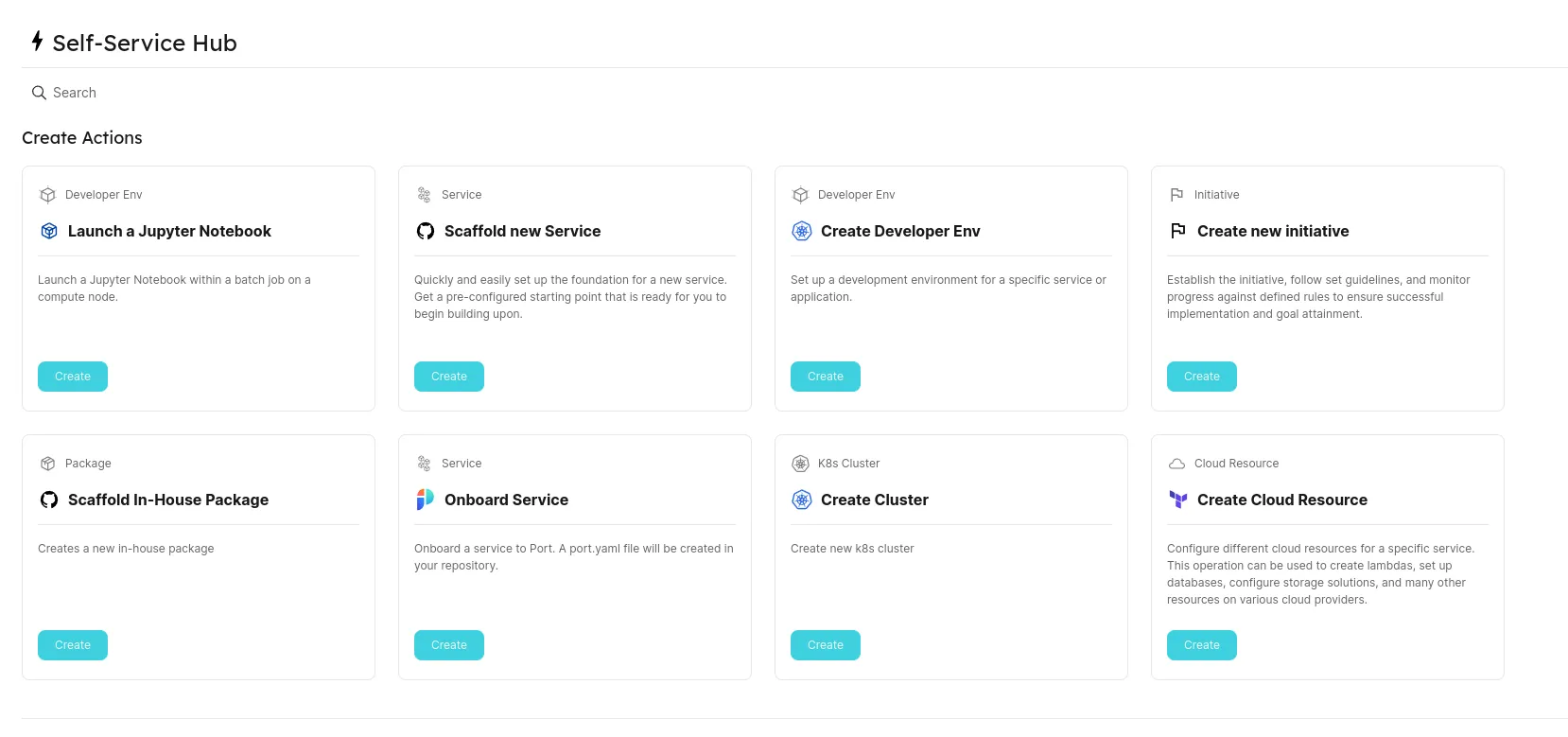
L'idée étant de rendre les équipes plus autonomes tout en proposant une couche d'abstraction au-dessus de la complexité de la plateforme.
La définition des standards
Comme dit plus haut, une équipe ingénierie a de nombreux outils à disposition pour mesurer la qualité du logiciel produit, sa dette technique. Mais comment consolider tout cela ?
Qu'est-ce qui est acceptable en termes de temps passé en support ?
Quelles sont les technologies que l'on peut utiliser ?
Quelles sont les standards de déploiement et de monitoring à respecter ?
Est ce normal que l'équipe A soit à 100% de build success alors que la mienne est à 80% car on a introduit une quality gate Sonar ?
A petite taille, il est fréquent de lister les standards dans une "Definition of Done" mais cela montre vite ses limites. Ici, on se limite à lister les tâches qui doivent être faites pour considérer un développement terminé. On ne parle pas des standards attendus sur le RUN en production. Et comment monitorer cela à l'échelle ?
La version initiale est souvent liée aux outils de base : Sonar et sa quality gate, la CI, parfois quelques métriques sur Jira.
Dès qu'on cherche à rassembler des informations et quand l'équipe a une taille plus importante, il devient intéressant de déverser des données dans une base de données pour faire des tableaux de bords adaptés :
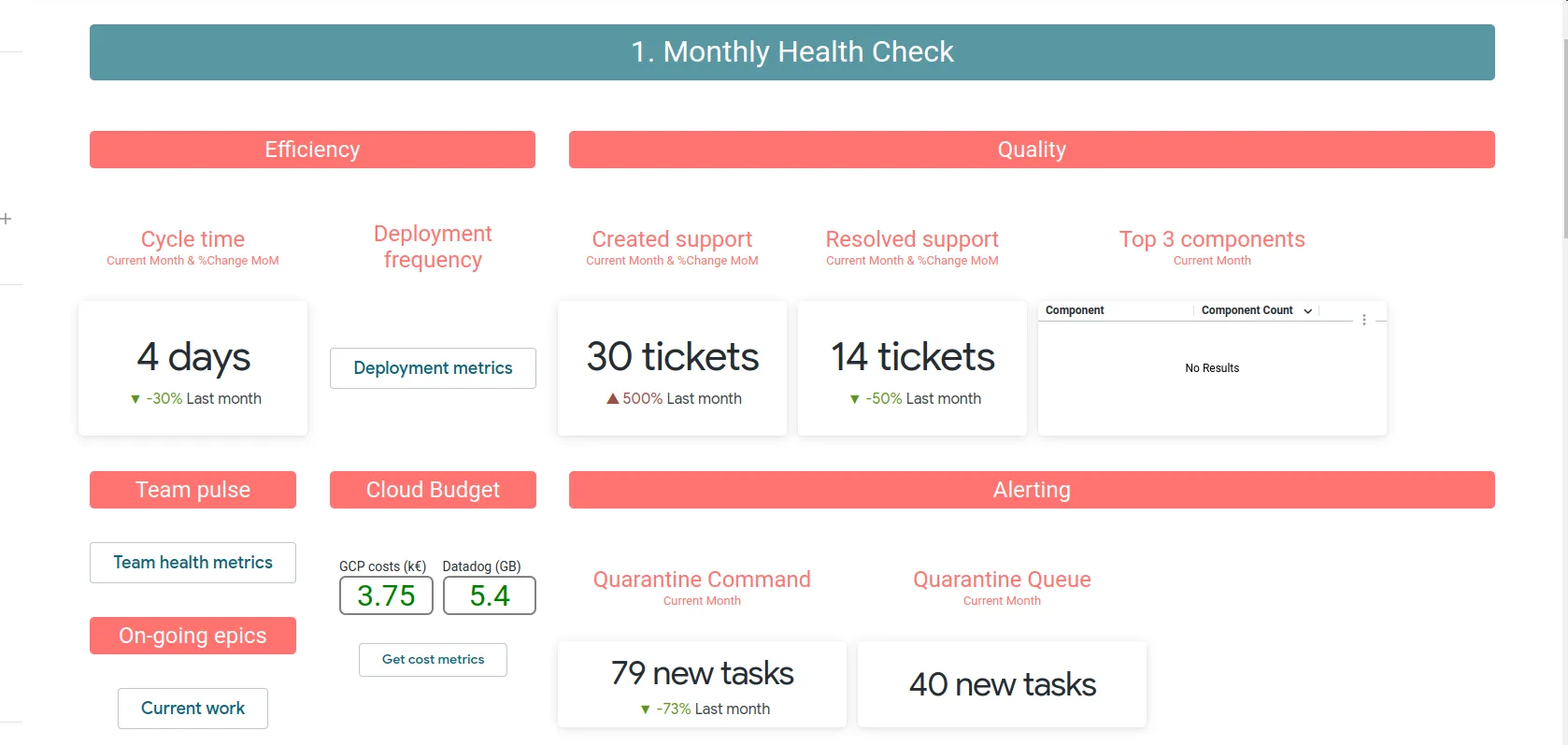
Ou bien d'utiliser des outils de dev analytics comme Haystack, echoeshq ou swarmia.
Je ne les ai pas testés personnellement, car on a passé du temps à construire ces analytiques de notre côté.
Ce ne sont pas toujours des outils simples à prendre en main, car il faut aussi l'accompagner de pratiques de dev (des labels sur les PR etc...)
Et nous avions souvent besoin d'analyses ad hoc que ces outils ne fournissent pas, comme le taux d'ownership d'une app, ou le suivi d'une migration
Enfin ces outils ne traitent pas un de nos besoins principaux : le Service Catalog.
Mais je n'en suis pas spécialiste et je serais ravi d'avoir des retours d'expériences sur le sujet si vous en avez.
Avec un Internal Developer Portal, on commence à pouvoir véritablement mettre en place des objectifs par équipe et des niveaux de qualités à atteindre.
Exemple avec getport :
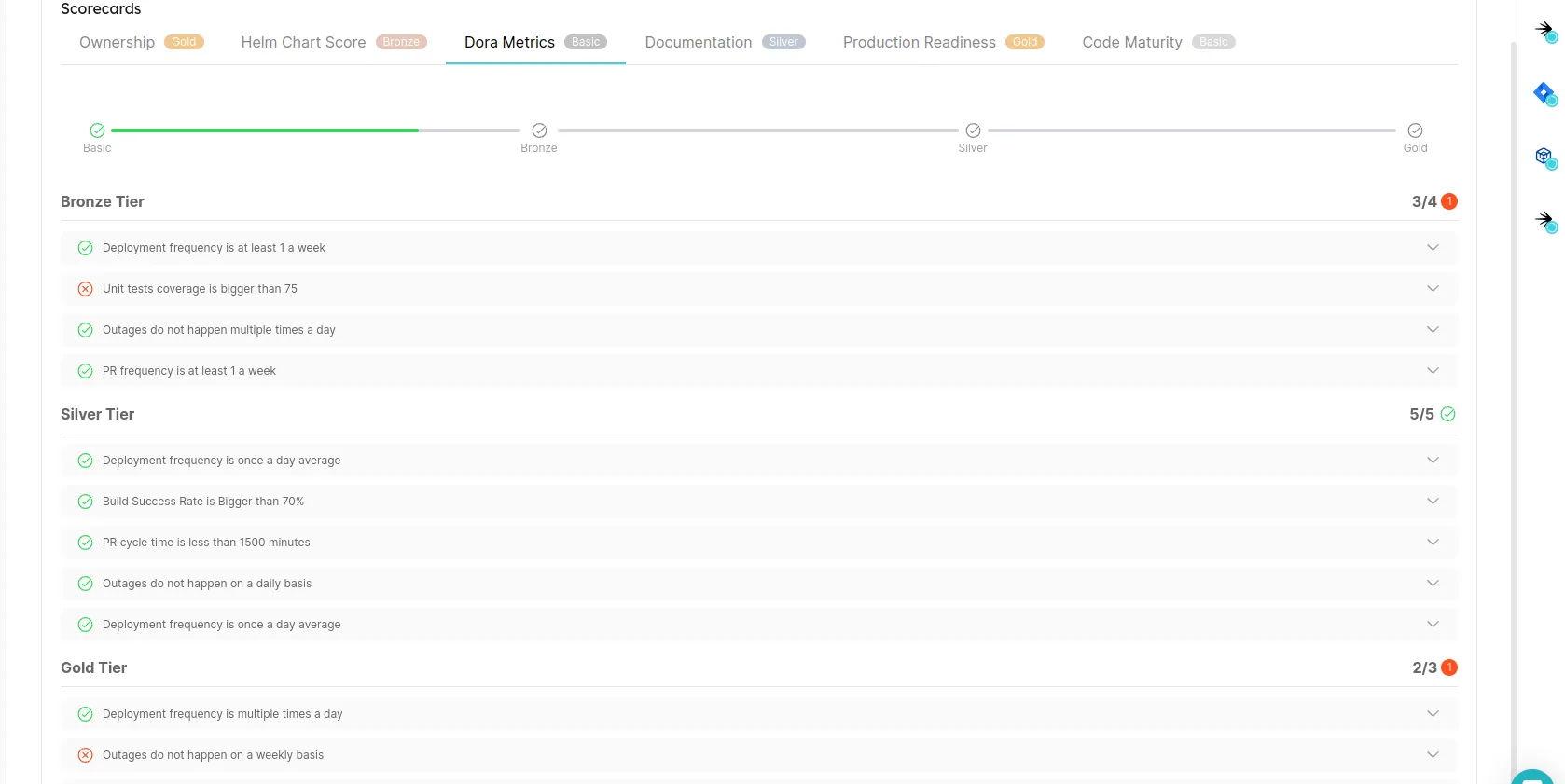
ou avec Configure8

Le cost management
J'aurais pu regrouper la section sur les standards et le cost management et je dirais que suivre ses coûts est un critère que je place dans les Scorecards des équipes.
Mais j'aime bien séparer cet item. De nombreuses équipes développent sans prendre garde aux coûts, car ceux-ci sont parfois difficiles à obtenir avec le bon niveau de granularité, d'autant plus agrégé avec le reste des informations (l'uptime, les dépendance etc...)
Pourtant, pouvoir détecter les anomalies, voir les évolutions dans le temps, les pics sont tout autant important que de monitorer son temps de cycle ou sa fréquence de déploiement.
Un bon IDP doit pouvoir rassembler ces informations et les mettre à disposition.
Configure8 a une très bonne démo à ce sujet :
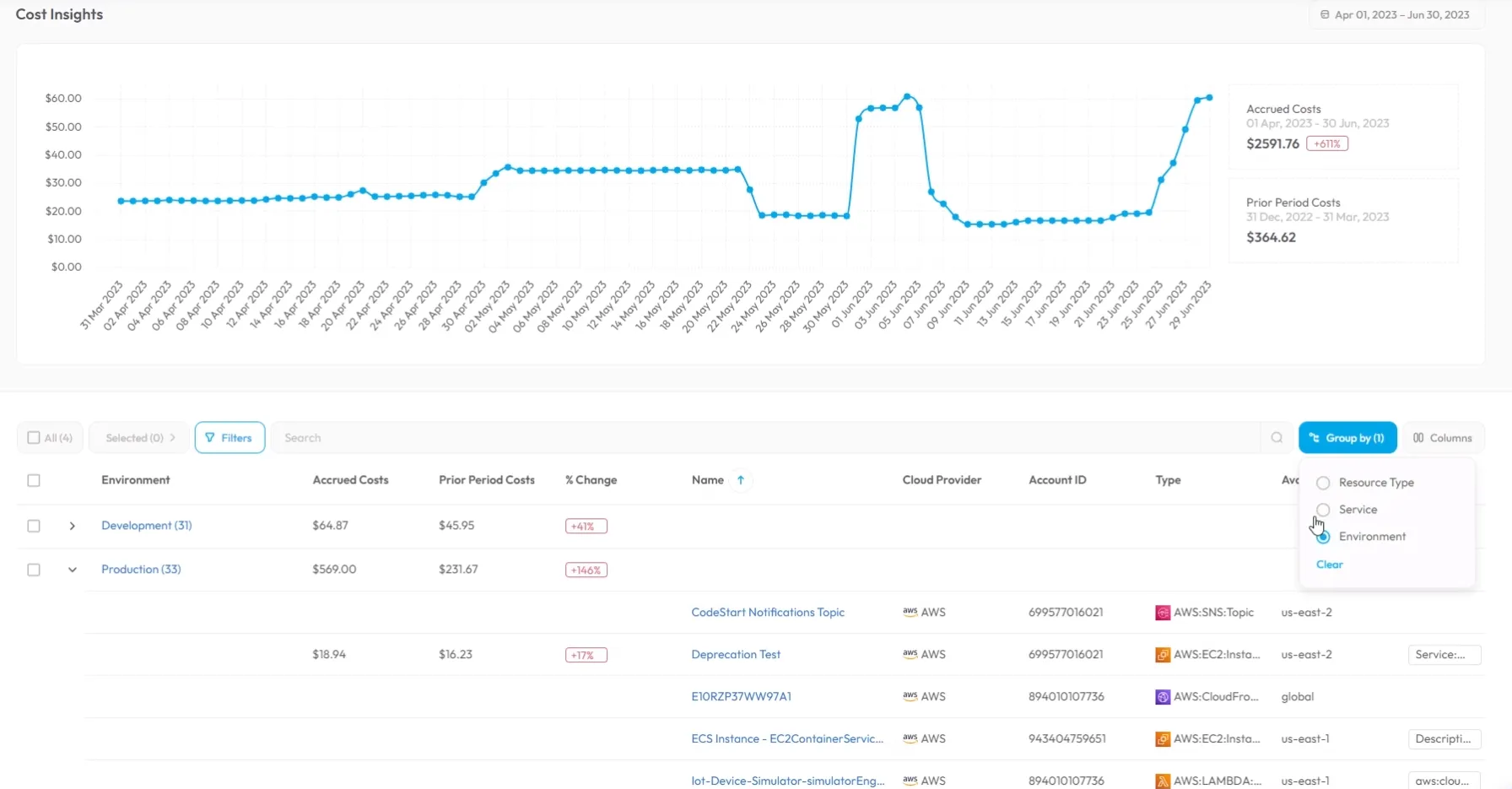
Buy Vs Build
Si vous avez suivi jusqu'ici, je vous disais que vous aviez sans doute déjà un Internal Developer Portal, mais peut-être très partiel par rapport à ce que je vous ai décrit ensuite : service catalog, automatisation, définition des standards et cost management.
Il y a sans doute plusieurs publics ici.
Écartons le cas le plus simple.
- Vous faites partie d'une équipe de moins de 10/15 personnes.
- L'ensemble de votre usine logicielle se résume à votre CI et quelques outils annexes.
- Vous utilisez majoritairement un monolithe.
- Vous n'êtes pas dans le cloud ou alors sur un PAAS.
Alors, il y a peu de chances que vous ayez besoin d'avoir plus que votre CI et votre PAAS pour l'instant.
À partir de 50/100 personnes, sur un produit composé d'une multitude de services, par nature très distribué, vous devriez commencer à vous poser des questions.
Depuis 2020, il existe une brique open source permettant de construire son propre IDP "gratuitement". Il s'agit de Backstage, offert à la communauté par Spotify.
Pour l'anecdote, chez Malt la première mention de Backstage sur notre slack remonte à 2020 et c'est paradoxalement notre CEO Vincent Huguet qui poste l'information :
À l'époque, l'outil nous paraît très bon, mais en 2020 nous sommes une cinquantaine et l'effort de mise en place pour le gain attendu ne nous semble pas intéressant à ce moment-là.
Et pourtant, en y repensant, nous avons fini par reconstruire notre propre IDP à base de Grafana, jobs d'ETL divers et variés, outils de dataviz.
Depuis 2020, de nombreux produits sont apparus en SAAS (avec parfois des options self hosted) :
- getport
- configure8
- cortex
- opslevel
- atlassian compass
- roadie
Donc, Buy or Build ?
Nous sommes justement en pleine réflexion et le Buy a pour l'instant notre préférence.
Nous avons fait un calcul basique.
Pour un gain entre 5 et 10%, sur une équipe de 50 personnes, j'estimais mon gain plus haut entre 250 et 500k.
Pour mettre en place un IDP custom, sur la base de Backstage, j'envisage 3 personnes sur 2 mois pour un premier effort et 1 personne ensuite par mois pour sa maintenance.
Le coût remonte à chaque nouvelle intégration et chaque nouvelle mise à jour.
On peut considérer que mon coût total oscille entre 160 et 200k. C'est sans doute optimiste.
Pour un SAAS, il faut compter 1 personne à temps plein pour son setup et ensuite un coût de maintenance équivalent à une demi personne par mois.
Le coût total oscille entre 50 et 100k par an.
Ensuite il y a le coût par utilisateur qui oscille entre 20 et 50 euros par utilisateur et par mois.
Pour 50 personnes ce sera donc entre 12 et 30k.
Première chose à noter, dans les deux cas, c'est intéressant comparé aux gains attendus de 500k.
Par contre le gain entre le buy et le build change en fonction de la taille d'équipe.
Avec mes hypothèses à la louche, je dirais que tant qu'on ne dépasse pas 200 personnes, le choix de de prendre un SAAS reste plus avantageux.
Ce sera moins vrai par la suite, même si le coût de changer d'outil n'est jamais négligeable. Il y a forcément un effet d'échelle qui rend le choix SAAS moins optimal.
Chez Malt nous étudions donc sérieusement la question après avoir passé beaucoup d'énergie sur un ensemble de briques faites maison. Nous nous orientons plutôt sur une solution en SAAS que vers Backstage dont le coût humain nous semble trop important à notre taille.
Mais nous allons faire notre possible pour que tous les pipelines de données qui alimentent l'IDP soient le plus réutilisables possible.
A dans quelques mois pour un update sur ce sujet.


